Data Stack
We'll explain which data stack is behind HelloDATA BE.
Control Pane Portal
The differentiator of HelloDATA lies in the Portal. It combines all the loosely open-source tools into a single control pane.
The portal lets you see:
- Data models with a dbt lineage: You see the sources of a given table or even column.
- You can check out the latest runs. Gives you when the dashboards have been updated.
- Create and view all company-wide reports and dashboards.
- View your data tables as Data Marts: Accessing physical tables, columns, and schemas.
- Central Monitoring of all processes running in the portal.
- Manage and control all your user access and role permission and authorization.
You can find more about the navigation and the features in the User Manual.
Data Modeling with SQL - dbt
dbt is a small database toolset that has gained immense popularity and is the facto standard for working with SQL. Why, you might ask? SQL is the most used language besides Python for data engineers, as it is declarative and easy to learn the basics, and many business analysts or people working with Excel or similar tools might know a little already.
The declarative approach is handy as you only define the what, meaning you determine what columns you want in the SELECT and which table to query in the FROM statement. You can do more advanced things with WHERE, GROUP BY, etc., but you do not need to care about the how. You do not need to watch which database, which partition it is stored, what segment, or what storage. You do not need to know if an index makes sense to use. All of it is handled by the query optimizer of Postgres (or any database supporting SQL).
But let's face it: SQL also has its downside. If you have worked extensively with SQL, you know the spaghetti code that usually happens when using it. It's an issue because of the repeatability—no variable we can set and reuse in an SQL. If you are familiar with them, you can achieve a better structure with CTEs, which allows you to define specific queries as a block to reuse later. But this is only within one single query and handy if the query is already log.
But what if you'd like to define your facts and dimensions as a separate query and reuse that in another query? You'd need to decouple the queries from storage, and we would persist it to disk and use that table on disk as a FROM statement for our following query. But what if we change something on the query or even change the name we won't notice in the dependent queries? And we will need to find out which queries depend on each other. There is no lineage or dependency graph.
It takes a lot of work to be organized with SQL. There is also not a lot of support if you use a database, as they are declarative. You need to make sure how to store them in git or how to run them.
That's where dbt comes into play. dbt lets you create these dependencies within SQL. You can declaratively build on each query, and you'll get errors if one changes but not the dependent one. You get a lineage graph (see an example), unit tests, and more. It's like you have an assistant that helps you do your job. It's added software engineering practice that we stitch on top of SQL engineering.
The danger we need to be aware of, as it will be so easy to build your models, is not to make 1000 of 1000 tables. As you will get lots of errors checked by the pre-compiling dbt, good data modeling techniques are essential to succeed.
Below, you see dbt docs, lineage, and templates: 1. Project Navigation 2. Detail Navigation 3. SQL Template 4. SQL Compiled (practical SQL that gets executed) 5. Full Data lineage where with the source and transformation for the current object

Or zoom dbt lineage (when clicked):

Task Orchestration - Airflow
Airflow is the natural next step. If you have many SQLs representing your business metrics, you want them to run on a daily or hourly schedule triggered by events. That's where Airflow comes into play. Airflow is, in its simplest terms, a task or workflow scheduler, which tasks or DAGs (how they are called) can be written programatically with Python. If you know cron jobs, these are the lowest task scheduler in Linux (think * * * * *), but little to no customization beyond simple time scheduling.
Airflow is different. Writing the DAGs in Python allows you to do whatever your business logic requires before or after a particular task is started. In the past, ETL tools like Microsoft SQL Server Integration Services (SSIS) and others were widely used. They were where your data transformation, cleaning and normalisation took place. In more modern architectures, these tools aren’t enough anymore. Moreover, code and data transformation logic are much more valuable to other data-savvy people (data anlysts, data scientists, business analysts) in the company instead of locking them away in a propreitary format.
Airflow or a general Orchestrator ensures correct execution of depend tasks. It is very flexibile and extensible with operators from the community or in-build capabiliities of the framework itself.
Default View
Airflow DAGs - Entry page which shows you the status of all your DAGs - what's the schedule of each job - are they active, how often have they failed, etc.
Next, you can click on each of the DAGs and get into a detailed view:
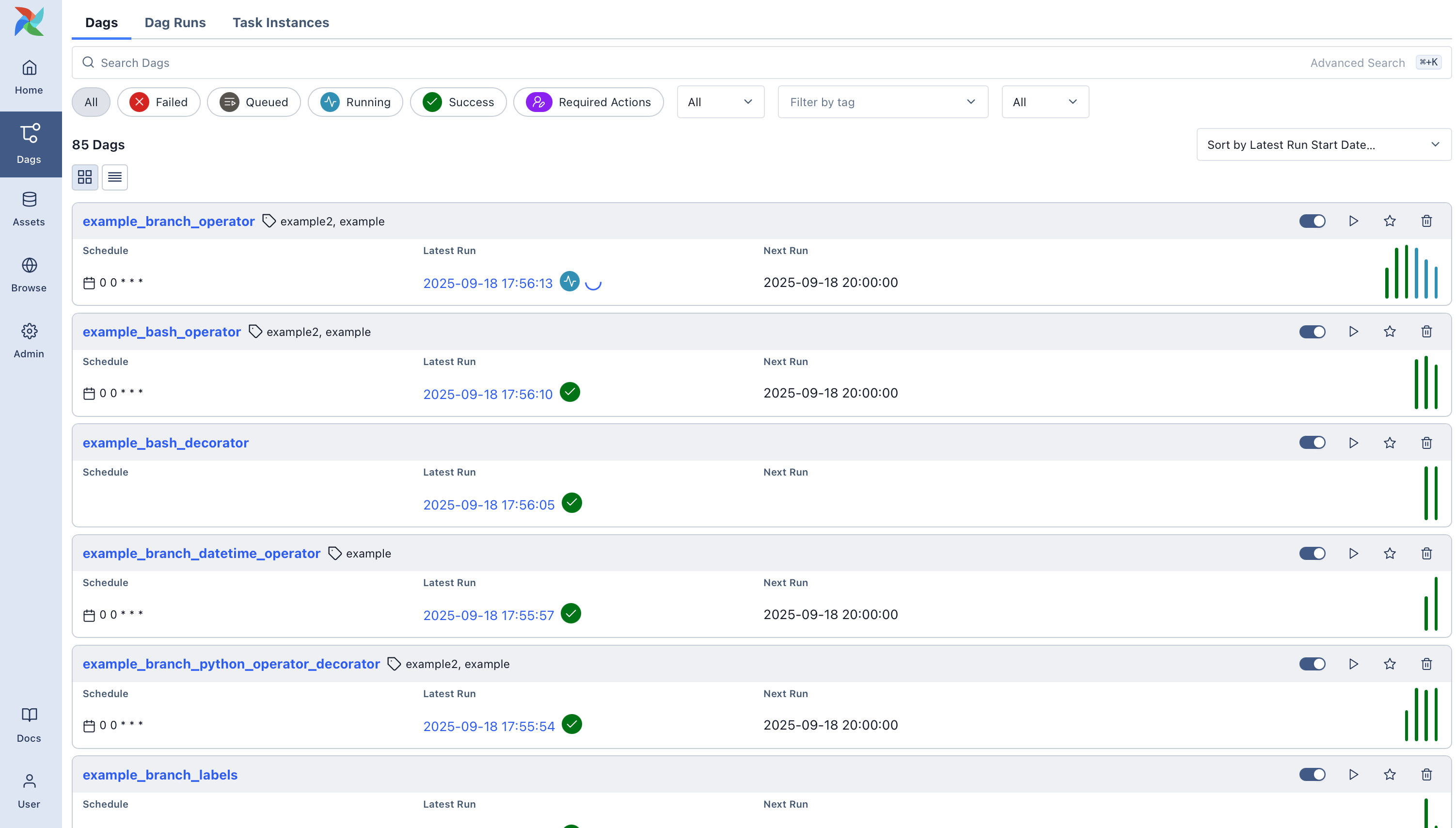
Airflow operations overview for one DAG
- General visualization possibilities which you prefer to see (here Grid view)
- filter your DAG runs
- see details on each run status in one view
- Check details in the table view
- Gantt view for another example to see how long each sub-task had of the DAG


Graph view of DAG
It shows you the dependencies of your business's various tasks, ensuring that the order is handled correctly.

Dashboards - Superset
Superset is the entry point to your data. It's a popular open-source business intelligence dashboard tool that visualizes your data according to your needs. It's able to handle all the latest chart types. You can combine them into dashboards filtered and drilled down as expected from a BI tool. The access to dashboards is restricted to authenticated users only. A user can be given view or edit rights to individual dashboards using roles and permissions. Public access to dashboards is not supported.
Example dashboard

Supported Charts

IDE - Juypter Notebooks with Jupyter Hub
Jupyter Notebooks and Jupyter Hub is an interactive IDE where you can code in Python or R (mainly) and implement your data science models, wrangling and cleaning your data, or visualize the data with charts. You are free to use what the Python or R libraries offer. It's a great tool to work with data interactively and share your results with others.
Jupyter Hub is a multi-user Hub that spawns, manages, and proxies multiple instances of the single-user Jupyter notebook server. If you haven't heard of Jupyter Hub, you most certanily have seen or heard of Jupyter Notebooks, which turns your web browser into a interactive IDE.
Jupyter Hub is encapsulating Jupyter Notebooks into a multi-user enviroment with lots of additonal features. In this part, we mostly focus on the feature of Jupyter Notebooks, as these are the once you and users will interact.
 ]
]
Features
To name a few of Jupyter Notebooks features:
- Language of Choice: Jupyter Notebooks support over 40 programming languages, including Python, R, Julia, and Scala.
- Interactive Data Science: Jupyter Notebooks are a great tool for interactive data science. You can write code, visualize data, and share your results in a single document. It allows with most prominent libraries like Pandas, NumPy, Matplotlib, Apache Spark and many more.
- Share notebooks: In notebooks you can document your code along side with visualizations. When done, you can share your Jupyter Notebooks with others via link or by exporting them to HTML, PDF, or slideshows.
What Jupyter Hub adds on top:
- Customizable: JupyterHub can be used to serve a variety of environments. It supports dozens of kernels with the Jupyter server, and can be used to serve a variety of user interfaces including the Jupyter Notebook, Jupyter Lab, RStudio, nteract, and more.
- Flexible: JupyterHub can be configured with authentication in order to provide access to a subset of users. Authentication is pluggable, supporting a number of authentication protocols (such as OAuth and GitHub).
- Scalable: JupyterHub is container-friendly, and can be deployed with modern-day container technology. It also runs on Kubernetes, and can run with up to tens of thousands of users.
- Portable: JupyterHub is entirely open-source and designed to be run on a variety of infrastructure. This includes commercial cloud providers, virtual machines, or even your own laptop hardware.
Storage Layer - Postgres
Let's start with the storage layer. We use Postgres, the currently most used and loved database. Postgres is versatile and simple to use. It's a relational database that can be customized and scaled extensively.
S3 and SFTP
SFTP Access Architecture (S3 Integration)
The HelloDATA BE platform integrates secure file access and browsing through a modular architecture built on SFTPGo and Amazon S3 (or any other S3 alternative, like the MinIO).
- SFTPGo is deployed as a core component responsible for handling SFTP connections from users. It provides a secure and standards-compliant interface for accessing data.
- An SFTPGo sidecar container is deployed alongside each SFTPGo instance. This sidecar dynamically configures virtual folders based on the authenticated user’s data domain access, retrieved from HelloDATA's access control system.
- These virtual folders are mounted from backend object storage, such as Amazon S3 or MinIO, abstracting the storage layer from the user.
- The integration ensures that:
- Each user only sees folders and files relevant to their permissions.
- All data is accessed securely through the SFTP protocol.
- Underlying storage remains scalable, cloud-native, and cost-effective.
This architecture enables a consistent and user-specific file browsing experience within HelloDATA BE while maintaining secure, centralized data governance.
